Recently, my colleague, Pete Carpenter, described a proof of concept we carried out using Amazon Redshift as the data warehouse storage layer in a system capturing data from Oracle E-Business Suite (EBS) using Attunity CloudBeam in conjunction with Oracle Data Integrator (ODI) for specialised ETL processing and Oracle Business Intelligence (OBI) as the reporting tool.
In this blog I will look at Amazon Redshift and how it compares with a more traditional DW approach using, as my example, Oracle. I am not going to talk performance in absolute terms as your mileage is going to vary.
Redshift is the Amazon Cloud Data Warehousing server; it can interact with Amazon EC2 and S3 components but is managed separately using the Redshift tab of the AWS console. As a cloud based system it is rented by the hour from Amazon, and broadly the more storage you hire the more you pay. Currently, there are 2 families of Redshift servers, the traditional hard-disk based, and the recently introduced SSD family, which has less storage but far more processing power and faster CPUs. For our trials we looked at the traditional disk based storage on a 2 node cluster to give us 4TB of disk spread across 4 CPU cores. Apart from single node configurations, Redshift systems consist of a leader node and two or more database nodes; the leader node is supplied free of charge (you only pay for the storage nodes) and is responsible for acting as the query parser, coordinating the results from the database nodes, and being a central network address for user access.
The Redshift product has its origins in ParAccel and that in turn Postgres and thus supports ANSI SQL and the ODBC and JDBC Postgres drivers. In basic terms it is a share-nothing parallel processing columnar store database that supports columnar compression.
At the cluster level all sorts of robustness features come in to play to handle routine hardware failures such as a node or disk; regular automatic backups occur and on-demand backups can be made to S3 storage for DR or replication to other AWS networks. It is possible to dynamically change the number and or type of Redshift nodes in use, in effect a new cluster is spun up and the data copied from the existing system to the new before dropping the old system. The original database remains open for query (but not update) during the scale-out (or scale-down) process. As Pete Carpenter described, creating a new Redshift instance is a simple matter of completing a few web forms and waiting for the cluster to come up. Once up you can connect to the database using the master credentials you specified at cluster creation and then create databases, users, and schemas as required.
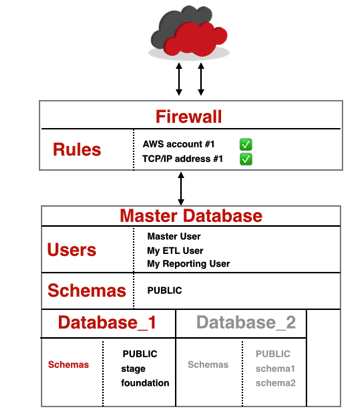
Although it is possible to run a Redshift database using the master user and the default database, good practice suggests that we do a bit more than this. In some ways Redshift is a little like the Oracle 12c database in that we can create additional databases within the master database, much in the style of plugable databases; a major difference comes with the concept of a USER. In Oracle 12c a user belongs to a plugable database, in Redshift all users belong to the master (container) database and can see any of the contained databases (subject to grants.) Schemas are logical groupings for objects and need not be aligned to database user names. Standard object and role grants allow users to access specific databases, schemas, and tables or to have role-rights such as administrator. The final aspect of security is outside the database and is in effect a firewall rule to permit any nominated AWS user or specified IP addresses to speak to the database listener; by default the rule is no inbound access. The diagram below is a block representation of how databases, users, schemas and firewall interrelate. Note user names are descriptive and not valid names!
A key point of difference between Amazon Redshift and Oracle is in how the data is stored or structured in the database. An understanding of this is vital in how to design a performant data warehouse. With Oracle we have shared storage (SAN or local disk) attached to a pool of processors (single machine or a cluster); however, Redshift uses a share-nothing architecture, that is the storage is tied to the individual processor cores of the nodes. As with Oracle, data is stored in blocks, however the Redshift block size is much larger (1MB) than the usual Oracle block sizes; the real difference is how tables are stored in the database, Redshift stores each column separately and optionally allows one of many forms of data compression. Tables are also distributed across the node slices so that each CPU core has its own section of the table to process. In addition, data in the table can be sorted on a sort column which can lead to further performance benefits; I will discuss this in the section on tables.
Not all of the database features we come to expect in an Oracle data warehouse are available to us in Redshift. The Redshift Developer Guide has the full rundown on what is available, but for now here is a short list of common DW features that are not going to be available to us.
In addition data types may not be exactly the same as those used in Oracle; for example DATE in Oracle has a resolution of 1 SECOND, DATE in Redshift has a resolution of 1 DAY.
The basic Oracle syntax to create a table works (as does CTAS, Create Table As Select), however there are additional items we can, and should, specify at table creation.
By default the data distribution style is EVEN, that is data is distributed between node-slices in a round-robin fashion, for performance we may wish to specify a distribution key column to allow a particular column to control how data is distributed; a similar concept to Oracle hash partitioning, and with the same sort of performance characteristics. We aim to create an even distribution of rows per slice (else one slice will take longer than the others to process its data) and by applying the same distribution to other tables that are commonly joined we can benefit from improved table joining performance as all of the rows are stored in the same node-slice. Sometimes it is more appropriate to replicate the whole table to each slice so that the data is always available to join without the need to move data to the same slice before joining; In such cases we set the distribution style to be ALL.
The second thing we can set on a table is the SORTKEY this specifies one or more columns on the table by which the data is ordered on data load (it can be the same column as the distribution key). Redshift maintains information on the minimum and maximum values of the sort key in each database block and at query time uses this information to skip blocks that do not contain data of interest.
Finally, we can elect to compress columns in the database. If we do not specify compression, the default is RAW (i.e. uncompressed) is used. For compressed data we can specify the compression algorithm used, different algorithms are better for certain data types and values. Compression may be data block based (DELTA, BYTE-DICTIONARY, RUN LENGTH, TEXT255 and TEXT32K) or value base (LZO and the MOSTLY compressions). This sounds daunting but there are two ways we can get compression suggestions from the database: using the ANALYZE COMPRESSION command on a loaded table and the AUTO COMPRESS feature of the COPY command, this however requires an empty non-compressed target table; copy is the Redshift equivalent of SQL/Loader and takes a flat file and inserts it into the database.
Let’s consider a simple table T1 with three columns, C1, C2 and C3. We can create this using a simple piece of DDL:
CREATE TABLE T1 ( C1 INTEGER NOT NULL, C2 VARCHAR(20) NOT NULL, C3 DATE );
I have not used any of the Redshift nice-to-have features for sorting, distribution, and compression of data. Note too, that I am using NOT NULL constraints, this is the only constraint type enforced in the database. This simple create statement creates database objects on each slice of the cluster, with one block per column per slice (1 slice = 1 CPU core) see the following diagram, note there is no table object stored in the database, it is a collection of columns.
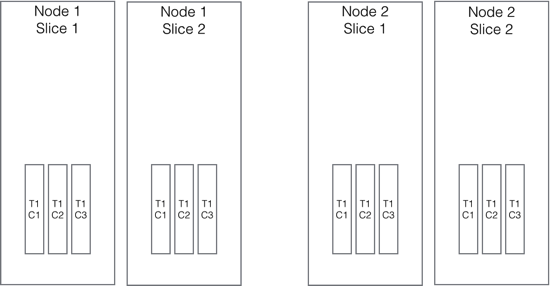
Without specifying a distribution key data is evenly spread across all slices. When a 1MB block for a column is full a new block is created for subsequent inserts on the slice. An empty table will occupy block size * number of columns * number of cores and our block size is 1MB this would be columns * cores megabytes
Using a distribution key effectively hashes the data on the key column by the number of cores. Adding a sort key declares that the rows in the table are ordered and potentially allows block elimination to kick in. If our sort key is, say, transaction date, it is likely that our data loads occur in transaction date order, however if we sorted on product code we might find each data load has data that needs to be inserted between existing rows. This does not happen, the data is still appended to the table and the table now needs to be reorganised to put the rows in order. There are two ways to achieve this, the VACUUM command that does an on-line reorg of the table and the potentially faster route of creating a copy table, populating it and then dropping the original and renaming the copy, of course this gives a little downtime when the original table is not available for access.
Applying compression, sort and distribution we get a DDL statement like:
CREATE TABLE T2 ( C1 INTEGER NOT NULL, C2 VARCHAR(20) NOT NULL SORTKEY DISTKEY, C3 DATE ENCODE DELTA ); This table uses column C2 as both the sort key and the distribution key; column c3 is compressed using delta compression - this is an efficient compression algorithm where most dates are ±127 days of the date of the previous row. If we wanted to use a multi-column sort key the DDL syntax would be like:
CREATE TABLE T1 ( C1 INTEGER NOT NULL, C2 VARCHAR(20) NOT NULL DISTKEY, C3 DATE ) SORTKEY (C3,C2);Multi-column distribution keys are not supported.
Redshift is designed for query and bulk insert operations; we can optimise query performance by structuring data so that less data is transferred between nodes in a join operations or less data is read from disk in a table scan. Choosing the right data sortkeys and distkeys is vital in this process. Ideally these key columns should not be compressed. Adding primary and foreign keys to the tables tells the optimizer about the data relationships and thus improves the quality of query plan being generated. Of course up to date table stats are a given too; tables must be ANALYZEd when ever the contents changes significantly and certainly after initial load. I feel that we should collect stats after each data load.
For a FACT + DIMENSIONS data model (such as in the performance layer of Oracle’s Reference Data Warehouse Architecture) it would be appropriate to distribute data on the dimension key of the largest dimension on both the dimension and the fact tables, this will reduce the amount of data being moved between slices to facilitate joins.
For optimal performance we should always ensure we include both the distribution keys and the sort keys in any query, even if they appear to be redundant. The presence of these keys forces the optimizer to access the tables in an efficient way.
For best data load performance we insert rows in bulk and in sortkey order. Redshift claim best performance comes from using the COPY command to load from flat files and as second best the bulk insert SQL commands such as CTAS and INSERT INTO T1 (select * from T2);. Where Redshift performs less well is when we use certain kinds of ETL steps in our process, particularly those that involve updating rows or single row activities. In addition loading data without respecting the sort key leads to performance problems on data query. If data update is essential we have two real options: we move our ETL processes to a conventional database hub server (perhaps using ODI) and just use Redshift to store pre-transformed data; or we revise our ETL processes to mimimize update activity on the Redshift platform. There is some scope to optimize updates by distributing data on the update key but another approach is to use temporary tables to build the results of the update and to replace the table with the results of the merge. This requires a bit of inventiveness with the ETL design but fortunately many of our required SQL constructs including analytic functions are there to help us.

Use Network Graphs for Data Analysis Python is one of the most capable and flexible data analysis tools out there. The data to be analysed comes in different formats and with different requirements for analysis. Some data is best represented and analysed as a network graph. A good example of
Janis Rumnieks Aug 19, 2024 • 6 min read
Python's NetworkX library offers a simple yet powerful entry point into the world of network graph construction and analysis. Let us build a directional graph with three types of nodes, similar to entities in a relational database: * Author, * Book, * Reader. import networkx as nx G = nx.DiGraph() authors
Janis Rumnieks Aug 13, 2024 • 5 min read
When you have a front end built on APIs, but aren’t familiar with the API commands, you can use Wireshark to find the endpoint and body of commands being executed on the front end. For example, if you want to find out how to start a process in Oracle